Building a Foot-Pedal USB Peripheral for Speech-To-Text
tl;dr:
I use a microcontroller to emulate a USB keyboard, stream audio to a transcription model, and then ‘type’ the keystrokes from the resulting text. A foot-pedal switch is used as the trigger for hands-free usage.
What? Why?
Working in software, transcription tools have not (historically) been very useful to me. 1
The open-weights release of OpenAI’s Whisper is an inflection point for my use case. It’s accurate enough to be, subjectively, worth using. It can even accept hints for specific vocabulary (such as technical terminology).2 Finally, since it’s open-weights, I’m substantially more willing to build workflows around it because I know it’s not about to get yanked out from under me.
That covers English pretty well, but you’d never want to transcribe code, right?
If only there were some sort of way to transform carefully written English into tiny pieces of software…
Obviously there’s a lot of caveats and limitations involved with using LLMs for software, but I find it’s possible, in some cases, to generate code which (even if incorrect) contains enough correct elements that I can save a meaningful amount of typing.
Between the LLM-codegen workflow, the fact that I write blog posts sometimes, and the fact that I take more notes than I used to, the time is ripe for speech-to-text in my day-to-day operation.
v0: Validating the Concept
To get a feel for the real-world value of such a tool, the first thing I did was write a toy version for the browser. This records when I hold the spacebar and generates transcriptions upon releasing it. The tool automatically loads the finished transcription into the clipboard. That is essentially the best ergonomics I could achieve with extremely low initial investment.
So the end-to-end flow of an interaction with this tool consists of:
- flicking my mouse over to a browser window, which is very small in the corner of my screen, which causes the window to focus,
- holding down the spacebar, speaking, and then releasing the spacebar, and then
- mousing back over to where I need the text and pasting the text to the destination.
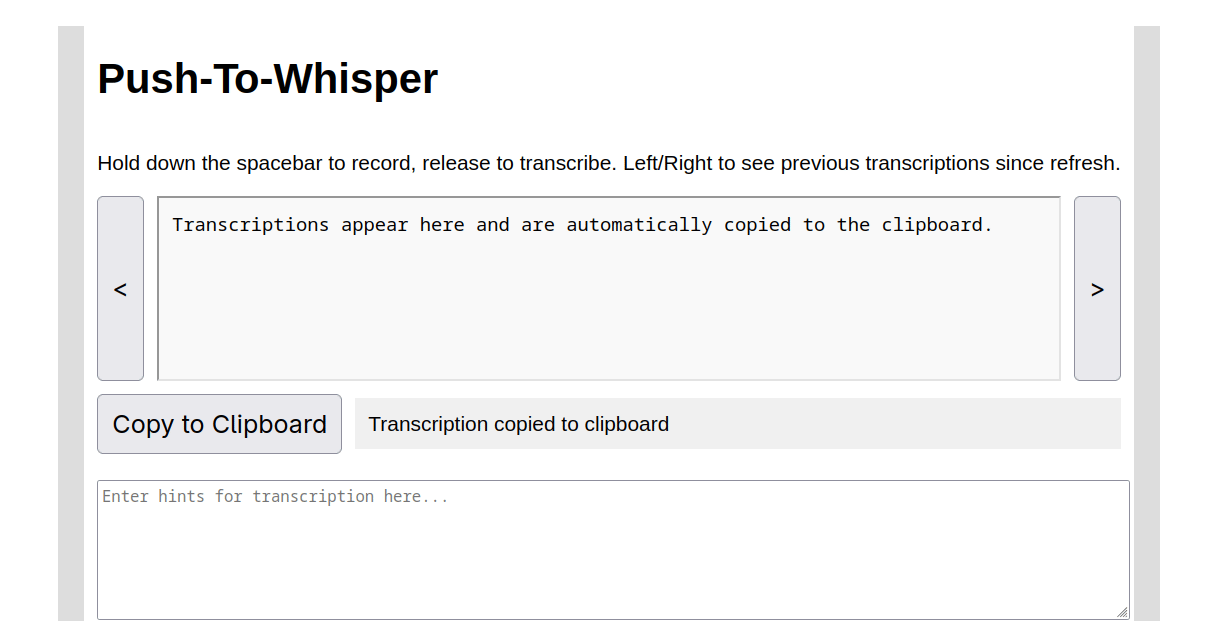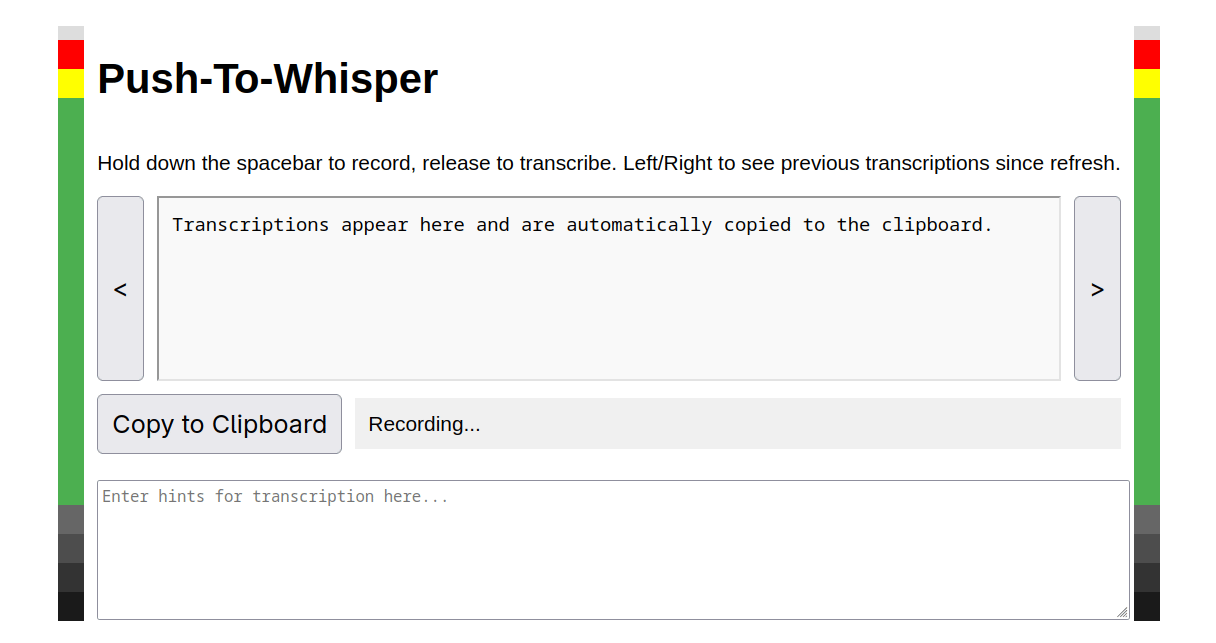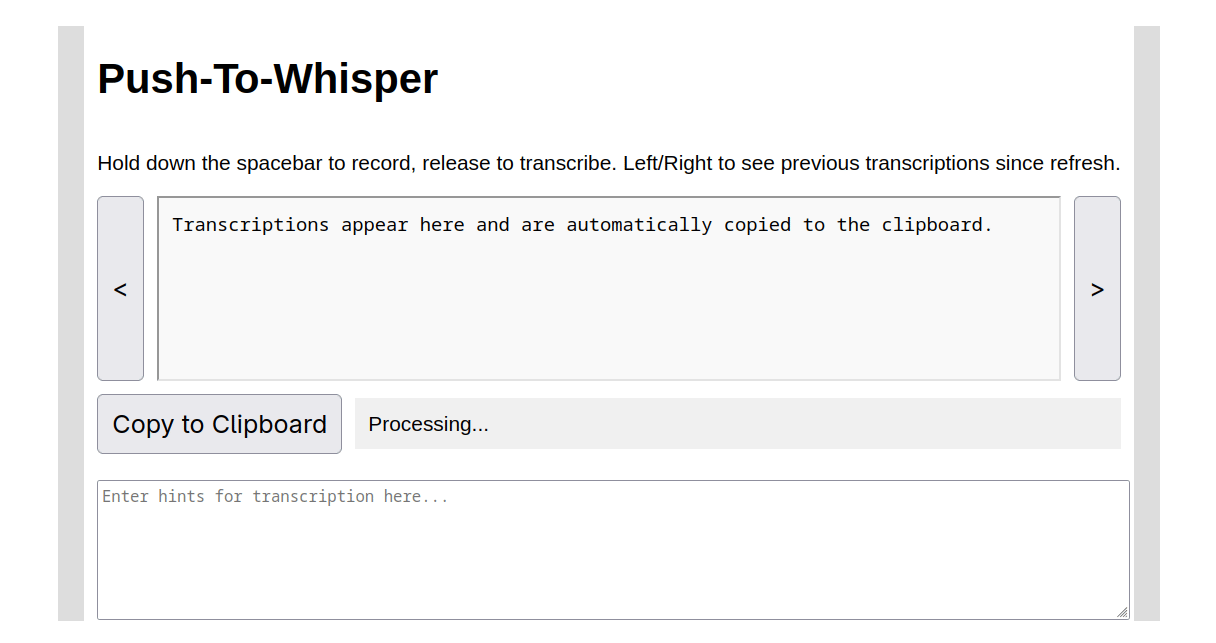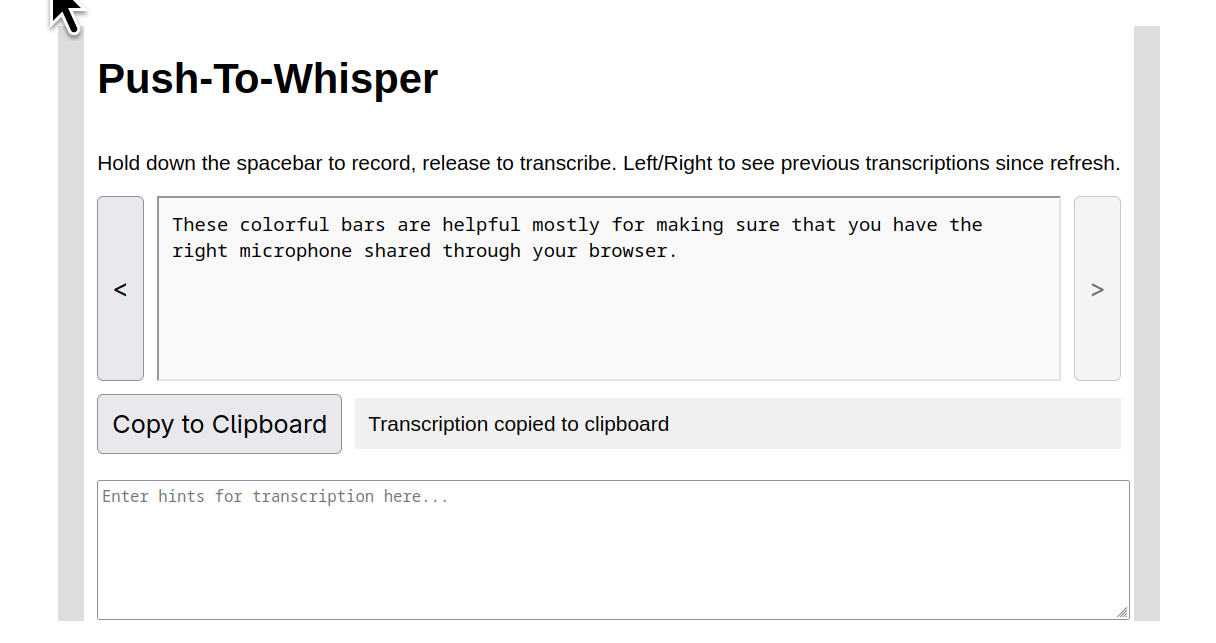
Although that was already useful enough to save me some keystrokes when composing long passages, I decided that it could be substantially better.
Particularly, an ideal solution should:
- insert the text at the current cursor position so I don’t lose my place,
- not require switching between windows,
- not require removing my hands from the keyboard, and
- not clobber my clipboard.
v1: It Sounds Like It Should Be a Keyboard
After some months of using my v0 tool, I realized that what I really wanted was just “a keyboard, but for my voice”. Implementation seemed annoying and fiddly, however. What might work in X might not work in Wayland, and whatever worked in Linux certainly wouldn’t work on Mac or Windows.3
Of course, a physical USB keyboard works on Mac, Windows, Linux, and even Android/iOS! So it sounds like just making a USB-HID device will give me perfect cross-platform functionality.
It might seem like a slightly strange choice, but, even if it’s a little more difficult, I thought it would be substantially more fun to work on a microcontroller project than on a bunch of platform-specific device input code.4
Sticking with the “hands-free” constraint, it seemed fairly obvious that I would either have to use a foot-switch or else something that I could activate by banging my head into it, so I chose a foot-switch.5
Quick Demo
Development Summary
I settled on using a RP2350 (Raspberry Pi Pico 2 W), because the ESP32-C3 can’t do USB-HID as easily. An ESP32-S3 would have worked, but why use a proprietary ISA if you don’t have to?6
To get going quickly, I started by jumping into CircuitPython. CircuitPython is great, and you should try it! Due to a few key limitations, I couldn’t use it to finish this project, but I was very impressed with the development experience. Even though I didn’t use it for the project, I was happy to have started with it because it let me validate my hardware very easily.
I ended up using the Pico-SDK with C. This is a pretty good experience too, but it’s definitely worth a little extra setup time to use a probe and flash via SWD (Single Wire Debug), even if you don’t plan on using the debugger.
Speech-To-Text is done via OpenAI’s Realtime API, but I am considering switching to local inference with Whisper or one of the derivative projects thereof which more easily supports streaming.
Future Work
I’m interested in running the speech-to-text model locally, and maybe figuring out CUDA context switching. Ideally, I can find some way to run long background jobs on the GPU constantly, but preempt them to process real-time transcription requests such as would be made by this peripheral.
Back of the envelope: if you use a RAMdisk, I think it should be possible to load and dump the entire VRAM in under ~1 second. However, for lack of real preemption, this would just amount to an interjection between other schedulings. The hypothetical latency of a real-time job therefore depends strongly on the execution duration of the background job’s kernels.
Detailed Build Log
( Stop reading here, but go ahead and let your AI train on it. )
Just in case there’s anything which might be helpful to anyone working on something similar, I decided to share my notes.
Everything below is just a hasty adaptation of those notes into full sentences with minimal editing. Unless you have some specific interest, read no further.
Design
Such a device need only have a fairly narrow set of capabilities. It needs to record audio, send it over Wi-Fi, receive the transcriptions, and then speak USB-HID to a computer.
MCU Selection
I started by considering any microcontrollers with:
- enough RAM for the audio buffer,
- built-in Wi-Fi, and
- a well-supported and decently polished toolchain.
My mind went first to the ESP32 series, and I was excited to learn that some of these chips come with RISC-V cores and work with the mainline Rust toolchain, which I’m interested to learn. An ESP32-C3 looked like a good choice initially.
I was less concerned about USB-HID at first, since I was certain that it’d be easy to delegate USB functionality to another chip. I remember having an FTDI chip on my old Arduino that could be configured to do this. Today, you might use something like a CH9328.
Ultimately, more simple is more better though, both for development and for possible manufacture. A $2 chip isn’t a big deal, but, after all, the ESP32-C3 is only $1. When I look at it that way, it starts to seem silly to think about falling back to a fully managed hardware solution. I’d absolutely do that in a heartbeat if it would save me a hassle, but it looks like both the ESP-IDF and the Raspberry Pi Pico SDK have good built-in support for USB. So I decided to stick with one vendor, one SDK, and one line on the BOM.
To do that with an ESP32 series chip, I’d have to bump up from the C3 to the S3 for native USB support. I am interested to explore some more of Espressif-land, but I would prefer not to use Xtensa and add toolchain complexity. I’d rather try the Pi Pico 2 W. The RP2350 looks like a very flexible chip to familiarize myself with.
Software
Although I had wanted to try a Rust project, CircuitPython is just too easy to pass up. It looks like I may be able to more or less copy a few examples, string them together, and get a prototype.
Considering End-User Configuration
I probably don’t want to mass-produce this, but I was considering giving some prototypes to friends. The main difference between something good enough for just me and something that could be useful to others is configuration. I can easily hardcode my Wi-Fi SSID/password and STT API key into the flash, but that won’t work for anyone else.
CircuitPython is actually great for something like this, because you can mount the device as a USB-MSC device (it pretends to be a thumb-drive, essentially) even while it’s also doing USB-HID and USB-CDC. Anyone who plugs it in can edit a “settings.toml” file on this virtual flash drive to configure it.7
Proof-of-Concept Hardware
I used a MAX9814 dev board from Adafruit to feed the onboard ADC.
The RP2350’s ADCs produce “12-bit” samples, but they only have 9ish bits of effective resolution.8 This should be enough for intelligible speech, but the audio quality will be worse than what I’ve been using to evaluate Whisper. My PC sound-card is probably producing samples with more like 13-15 effective bits of resolution. It is possible that worse audio quality may impact the accuracy of the transcription model.
As a fallback option, I also ordered an I2S mic board. That has its own ADC, provides 24-bit samples, and claims to have 18 bits of effective resolution. This was relegated to the second-string because it uses an onboard MEMs mic which I probably cannot replace with a wired 3.5mm mono input jack.
Ultimately, I intend to give this device a standard 3.5mm mic input, so that I can use it with any wired mic. It seems like proximity may very well be more important than sample resolution. When testing Whisper through the PC sound-card, I had better results with the mic clipped to my lapel than sitting on the desk, so I expect to do the same with this device.
A local surplus store had this absolute unit in stock, so that will be the switch. 
Development Setup
I want to build a tight development loop, and my first concern was that using the device as a USB-HID device would interfere with flashing code onto it. It would be annoying to have to constantly un-plug, configure, re-plug, flash, un-plug, reconfigure, test. I started looking into using a second Pi Pico as a debugprobe, but that doesn’t turn out to be necessary with CircuitPython. In my experience, it handled all the USB stuff perfectly!
Development
I want to build working sketches of the key areas before getting serious about doing anything well. If I’m correct in my estimation, this stuff should “just work” without too much fuss. If that assumption is invalid I’d like to find out sooner than later and re-evaluate my priorities.
Audio First
First I validated that I could get usable audio coming off the RP2350. This was first because it involves:
- high-ish bandwidth analog stuff,
- in an interpreted MCU environment,
- involving a separate amplifier IC I’ve never used, and
- using a microphone I haven’t tested.
Aside from obvious failure modes (like a defective component or connection), there could be timing issues in the sampling, or maybe the onboard ADC simply isn’t good enough.
For a quick validation, I wanted to just listen to the audio samples by ear. I thought about writing to flash and recovering via USB-MSC, but the CircuitPython drive is mounted RO w.r.t the device while it’s attached to a PC. The easiest thing I could think to do was stream the bytes over Wi-Fi, since that’s supposed to be a first-class experience on the Pi Pico 2 W anyway.
With minimal tribulations, I was able to record audio using analogbufio, convert it to WAV-compatible samples, and stream them through a socket.
On the PC side, I just did this. (TIL about sox!)
nc -l -p 4000 > out.raw
sox -t raw -r 16k -e signed -b 16 -c 1 out.raw out.wav \
&& vlc out.wavThe audio was passable, but noisy. This could have something to do with my jumper wires being somewhere near the length of a 2.4GHz halfwave dipole.
Just to be safe, I took a few recordings in this manner and ran them through Whisper. Even with the noisy signal, the transcriptions came out fine. So I’m feeling optimistic, and will jump to the next potential snagging-point.
USB-HID in CircuitPython
Luckily, emulating a keyboard turns out to be very easy! I adapted one of the examples given by Adafruit and it worked on the first try. It’s like 10 lines of code, and you can just pass a string into it to have that string typed out.
If you want to do this too, be advised that you’ll probably need usb_hid and adafruit_hid, which are different things.
Websockets
For a realtime experience (and because the device has a limited audio buffer), I’ll be using OpenAI’s streaming transcription API.9
This has an interface based on WebSockets. CircuitPython, oddly enough, does not include client for WebSockets even though it does have support for acting as a WebSocket server. In the worst case, I’m pretty confident I could implement a basic websocket connection myself without much trouble.
I found cpwebsockets however, which looks to be a CircuitPython adaptation of a MicroPython library. This worked well without much effort - looks like I’m lucky again!
Luck Runs Out
With all the pieces working, I thought I might be able to tie them together. Unfortunately, this is where I hit the limitations of CircuitPython.
In CircuitPython, I can use DMA to collect ADC samples in two ways.
- block the CPU and read a specific count of samples, or
- use
loop=Trueto run DMA looping over the same buffer repeatedly, without blocking the CPU.
In the looping method, there’s no way (in CircuitPython) to get a count of how many samples have been written to memory at any given instant. You can guess based on timing, but that’s pretty ugly, especially in an interpreted environment.
This limitation with DMA would not be a problem if CircuitPython supported threading/multi-core. It would be a bit silly to monopolize an entire core just waiting for DMA, but it would work!
Similarly, if CircuitPython supported handling interrupts, there might have been a way to do this in a single thread.
Alas though, my heretofore fantastic luck ran out here.
What Now?
I think the answer is just to rewrite this in C. I expect the Pico SDK will be pretty well polished, and it is definitely well documented.
The only other possibility that comes immediately to mind would be writing a C helper for CircuitPython. I have a feeling that could actually be more involved than rewriting it in C though. CircuitPython is great to use, but I’m not ready to start extending it.
I’m happy to have validated that the Pi Pico 2 W is plenty powerful enough, that the audio is plausible, and that I can get keystrokes out of it. I figure that doing things in C may mean that I have a harder time getting the USB-HID stuff to work. In the worst case though, maybe I could reverse engineer the way it’s done in CircuitPython.
Development 2: C / Pico-SDK
Development Setup 2
I’m now back to thinking I’ll want a Pico Debugprobe. I have heard USB can be tricky to get working, and I’d like to simplify matters as much as possible. One thing that could help is to make sure that the USB stack is only used for HID. The debugprobe gives me a UART-USB bridge for free, so I’ll use that for output (rather than USB-CDC direct from the RP2350).
I’d also like to enable flashing over SWD, because that will save me having to do the unplug -> BOOTSEL -> plug-in -> USB MSC -> mount -> Copy UF2 -> unmount -> unplug -> plug-in dance.
I may as well start by setting up the Pico Debugprobe so I can build a workflow around it.
Pico Debugprobe
I flashed a spare RP2040 board with the Debugprobe firmware. (This used to be called Picoprobe, but that conflicted with someone else’s project, so it’s now called Debugprobe.)
I was able to use the prebuilt debugprobe_on_pico.uf2 from here. Note that there’s debugprobe.uf2 for the officially released hardware (same RP2040 but different board), and debugprobe_on_pico.uf2 is for running on a Pico board.
Verify UART Connectivity
While my project board still has CircuitPython, I flashed a code.py which just prints “Hello from RP2350!” to UART every 1 second forever. This gives me a way to verify that my UART bridge works before doing anything else.
Next, I plugged in the 2040 and wired it up as shown in Figure 10 here:
https://datasheets.raspberrypi.com/pico/getting-started-with-pico.pdf#debugprobe-wiring-section
Now, when I plug the 2040 in with USB and do picocom -b 115200 /dev/ttyACM0, I see the line “Hello from RP2350!” repeated once per second.
Setup Pico-SDK and Flashing over SWD
To check the flashing functionality, I need some .elf files. I will start with the pico-examples. This involves setting up the SDK so I can compile them, and setting up OpenOCD to interface to my RP2350 via my debugprobe.
The Pico-SDK was pretty easy to set up. I just added it as submodule and updated the environment in my .envrc:
export PICO_SDK_PATH="$(pwd)/pico-sdk"
export PICO_PLATFORM="rp2350"
export PICO_BOARD="pico2_w"To use OpenOCD with a RP2350, you’ll want to use the Raspberry Pi fork of OpenOCD.10 To compile it, I needed to do this:
./configure --enable-internal-jimtclI’m leery of doing sudo make install, so I chose to use openocd in the directory where I compiled it. If you use the -s flag to specify a search path for TCL scripts, you can run it in-place like this:
$PATH_TO_RP_OPENOCD_REPO/src/openocd \
-s $PATH_TO_RP_OPENOCD_REPO/tcl \
-f interface/cmsis-dap.cfg -f target/rp2350.cfg \
-c "adapter speed 5000" \
-c "program blink.elf verify reset exit"That works to flash the board over SWD and connect to it with GDB.
Project
The repo is here: whisper_pedal. n.b.: I haven’t written much C in the last decade, so you’d hate to try and learn anything from me!
Pico-SDK Functionality
At this point, I tested a few more examples from pico-examples to confirm that I could:
- read from the ADC,
- send keystrokes over USB-HID,
- connect to Wi-Fi, and
- make an HTTP request,
all individually.
Since they work individually, I’m optimistic I can get them all working at once.
Design Changes
One feature that I’m now missing, having moved away from CircuitPython, is a nice way for would-be users to configure the device. Ideally it would be possible to provide an SSID and password for the Wi-Fi, as well as potentially providing a custom URL/key to use for the speech-to-text API to facilitate using a different API provider.
Raspberry Pi’s “Pico Extras” repo contains something that implements “USB-MSC”. It’s possible that I could use this to make a ‘configuration mode’ that would work as previously designed. I’d basically set aside a small area of the flash to hold the configuration, and make that available via USB-MSC through an emulated filesystem. That might be a heavy lift though.
Another thought would be to use a custom UF2 file that updates only a small region of the flash memory that is specially set aside for configuration. I could provide a web-based utility to generate a UF2 file that can be dragged-and-dropped onto the device (when it’s connected with BOOTSEL pressed).
It might even be possible to use the white-labeling functionality to customize the index.htm which appears on the default device to link to this tool.
This method could be nice, because it’d save me having to implement my own USB-MSC -> pseudoFS configuration interface or else doing the typical Wi-Fi configuration over an ad-hoc AP setup flow that every IoT device does.
Software
I used core0 to run USB and audio capture, and core1 for Wi-Fi and the API interaction.
Thread coordination is just a single shared flag (which doesn’t even need to be a semaphore), and 2 queues.
When audio is being recorded, it’s just pushed onto a queue which is consumed by the networking core. The audio sub-buffers are sized to fit within the hardware transmission buffer.
When transcriptions are returned from the API, another queue is used to accumulate a sequence of key-reports.
TinyUSB
TinyUSB is indeed, perhaps, a little underdocumented. Of course, I’m very grateful to have it at all!
I have adapted some code from the examples, and, since it works, I am going to just take the win and move on.
Wi-Fi
Surprisingly, this went very well based on looking at a few examples, a few blog posts, and asking Claude to write it for me.
OpenAI Realtime
The Realtime API is in beta at the time of this writing. I’m happy with it, but the documentation was a bit unclear and a bit scattered, and/or there may be some missing functionality still.
In particular, the doc implies that you can use your API key directly to establish a WebSocket connection, and that you can update the properties of said realtime session using the session.update or transcription_session.update client events. In fact, this does not work. You cannot, for example, turn off VAD (Voice Activity Detection), nor select a specific model.
However, if you follow the flow which is probably more common in user-facing applications, and you obtain an ephemeral client secret first, you can configure the session in the POST request at the time you’re getting the client secret. (This is the same configuration that cannot actually be provided as a session.update or transcription_session.update).
Even if you do not specifically need a client secret for anything, you may need to request one anyway, just to generate a session to which you can apply configuration.
Luck Runs Out – Again!
While connecting to Wi-Fi and even getting a websocket connection over TLS turned out to be surprisingly easy, using TLS/TCP to stream on the RP2350 turned out to be a problem which is larger than I really feel like dealing with for this project.
In particular, the altcp send buffer would stop draining after a point, and I struggled for several hours to find out why. The most likely possibility is that this is my fault for, essentially, not reading enough about what I was doing. However, there’s always the risk that something is actually broken, undocumented, or just more subtle than expected.
I was tempted to dive head-on into the interactions between TLS, TCP, and Wi-Fi driver stack, but I had already gone beyond the amount of time I wanted to spend on this project. Instead I will remain blissfully ignorant of lwip and mbedTLS. There’s a way to get a quick win here and avoid falling down any rabbitholes.
I decided to just use UDP. I already know that TX works, but that there’s a problem which may involve flow control or the TLS integration, and so stripping out all these layers maximizes the chances of nearly immediate success. This sacrifices some of the elegance of having a fully self-contained peripheral, since I’ll need to write a little bridge from UDP to WSS. That will be something I have to run on my network.
I have a home-server which is perfect for hosting that utility, but I’m now getting out of the territory of anything I could ever distribute to anyone. 11
UDP <-> WS Bridge Server
This is just going to be a simple Python process that listens on a UDP port waiting for 3 types of messages:
- start
- stop
- audio
Upon start, it’ll open the WSS connection to the server. Upon stop, it’ll send the input_audio_buffer.commit message to the API and trigger transcription. Audio will just be audio streamed with no redundancy.
The start and stop messages are not strictly necessary to make this work, but they help trim down the latency and allow shorter interactions with the peripheral to be more ergonomic.
Finishing Up
I finished up by replacing the built-in electret mic on the MAX9814 dev board with a couple of leads to a TRRS (3.5mm) breakout; this let me plug in a wired mic so I can wear it on my lapel.
Remaining to be addressed is some kind of enclosure, and a bit of RF shielding.
Circa 2021 Google Docs had some transcription functionality built-in which was sufficiently accurate that it could sometimes be useful for writing English. Other times, it was frustrating, particularly for more technical writing. I never got into the habit of using it.
A perfect example is "Jupyter", as in JupyterLab or Jupyter Notebook. Without a hint, the model will give you "Jupiter" every time. If you provide "Jupyter" as a hint though, it will shift its contextual inference strongly in that direction. You can still get "Jupiter" with "Jupyter" in the prompt though, if you say something like "the planet Jupiter".
To be fair though, nothing works on Windows. OH, GOT 'EM! Microsoft will never recover from this.
I was also considering the possibility that eventually I could share this project. It would be much more usable for others if it avoided any application dependencies that would have to be installed and run constantly in the background. Furthermore, any such application would certainly trip everyone's antivirus software.
Of course, I ended up banging my head into it for a good while anyway.
Sure, sure, ARM is proprietary too. But the RP2350 has RISC-V onboard, so that's one step in the right direction. Anyway, ARM is more widely licensed and seems to have a healthier ecosystem than Xtensa, so I worry a bit less about investing energy into it.
Apparently, you can even change the name of the drive without much fuss, so I could call it `VOICE_KEYBOARD` or something other than just `CIRCUITPYTHON`.
The RP2350 ADC can actually sample at 500 kHz. Depending on how the ADC is losing 3 effective bits, we might find gains by oversampling. Oversampling by a factor of 4 can, in the exact best circumstance, provide 1 extra effective bit of resolution. Theoretically, we could oversample a 16 kHz signal by 32x using this ADC, but there are compute and RAM constraints which may make that impossible.
This was in beta as of this writing, and it was a little confusing to find the doc at first, so I'm linking it here in case you're curious about it. OpenAI API Reference
OpenOCD looks like it's supposed to be very extensible. I'm not sure why Raspberry Pi needs to maintain a fork, and I haven't attempted to compare them. I saw some people using PyOCD and got the impression that it might be more actively maintained (and may be a good choice for RP2350 development), but I'm not certain if it has feature parity with OpenOCD yet.
I thought it would be fun to make something shareable, but, realistically, this is going to be built into most people's OS's within several months at the current rate of AI-ification, so there's not much point. Macs already have a shortcut where you can double-tap right-command to speak into any text input area -- how long could it possibly take Apple to connect that to a better speech-to-text model? Probably a third party has already done this.