Searching Podcasts - The First Step Towards Trends Analysis
tl;dr:
I’ve been processing podcast audio to build a semantic index. Currently my index has limited coverage over a subset of popular podcasts. I’m working towards trend analysis tooling, and have started by making a search frontend.
How?
Springboarding off of some tools I created earlier, I made a podcast tracker, started tracking ~100 popular feeds1 , and wired up an ingestion pipeline. This produces many segments of podcast content and their corresponding embedding vectors.
That data is pushed into Postgres, where it’s indexed. That vector index is enough to drive core similarity-search functionality. I say core functionality because this does not include re-ranking nor any lexical searching. I’m not currently aiming at making a good search or RAG system, rather I’m trying to validate and understand the primitive (similarity) that I will use for analyzing trends.
I have been wanting to try Phoenix, so I used that to build a search interface: 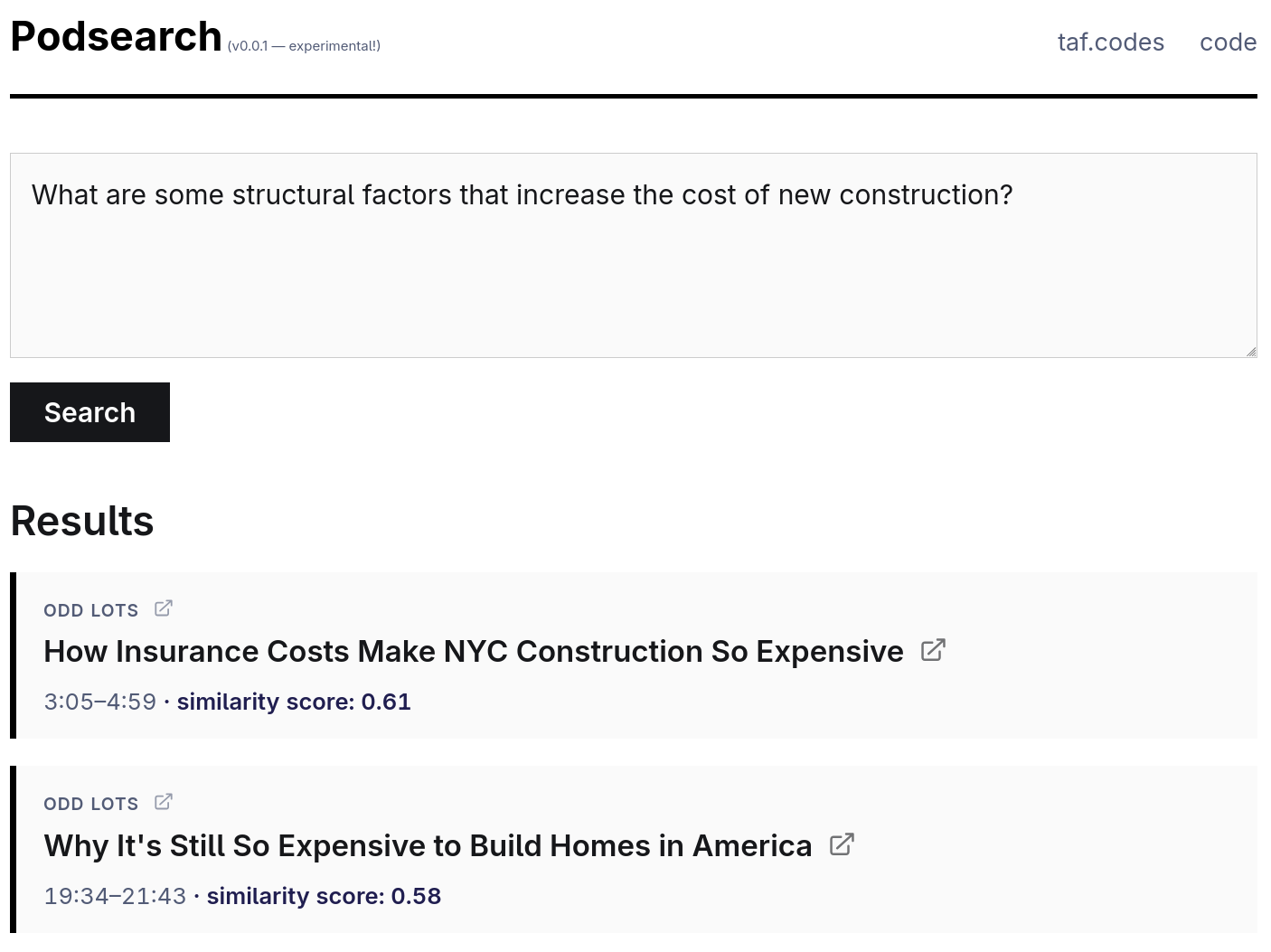
As you can see, I’m getting results roughly in line with what one might expect from such a system. The podcast segments from the example can be listened to at these links: [1] [2]. If you’re curious, you can read more about how this search works.
What’s next?
I’ve been running a lot of queries and have found that my results are frequently compromised by advertisements. Certain topics (those which tend to be most strongly associated with advertising campaigns) are essentially unsearchable. In other cases, the ads will merely dilute otherwise decent results.
Now that I think of it, it’s actually interesting to think about trends in advertisements2 , but that’s not what I want to look into right now. I’m going to try and do some filtering to mitigate their impact on my index.
After that, I’ll build some trend analysis features.
Build Log
(Skip this part unless you’re interested in the details.)
Podcast Tracking and Ingestion
This is managed by a simple app that tracks state in sqlite. Most operations it carries out are compositions of my existing (stateless) utilities.
Feeds are synchronized daily to track new episode releases. I noticed that some of these RSS/Atom feeds are large-ish (tens of MB), so I added some support for conditional request headers.3 This is mostly out of an abundance of consideration for the hosts of this data, but it could also allow me to sync more often.
As new episodes are discovered, they are downloaded. I’ll grab up to a few from each feed each night, which is enough to keep me current and to start working through the backlog of older episodes.
Downloaded episodes are transcribed using Whisper (v3-large-turbo). For clean, professionally recorded audio, I could not find substantial differences between v3-large and v3-large-turbo, and with turbo I can run decent batch sizes on my local GPU. Running this myself actually provides a substantial cost savings compared to using a transcription API.4
The generated transcriptions include timecode information. The breaks here often coincide with natural breaks in speech or pauses between speakers, so I use that information when chunking the text.
After this, I apply chunk-level filters. These are duration aware, so I can remove stuff like the odd chunk that may be leftover at the very end of an episode, is 5 seconds long, and just says “Thanks for listening!”. I also shoehorned some ad-filtering in at this stage, but more about that in my next post.
All remaining chunks are embedded. Then I push data to the Elixir/Phoenix project where it’s indexed.
Search Application
I’m really enjoying Phoenix so far. It was almost disappointing how well-structured it is, in that I had been expecting and looking forward to writing a bit more Elixir. For the first couple hours, I was skeptical about the amount of macros involved, but, in practice, everything seems to be assembled thoughtfully enough that one may not need to look behind them often.
For basic similarity search, the only things I needed beyond basic web-framework stuff were pgvector for Postgres, and some way to compute the query embeddings. Tempting though it was to compute them on the server and maintain full custody of the essential infrastructure, I was not about to rent a cloud GPU full-time nor even use a VPS with enough RAM to hold the weights of the embedding model. The second temptation was to do something serverless (or at least dynamic), but, with no volume, every visitor would hit cold-start latency. So I went with DeepInfra’s API, which seems to be performing acceptably.
Search is driven entirely by ANN operations in semantic embedding-space, so it behaves differently than keyword or text search. In general, it performs well at finding plausible results based on real meaning. None of the words in the query need to match any of the words in the content to find a match. In contrast, it cannot perform at all if you do want textual matches, such as names of individual human persons.5
I used claude-code to pick feeds, which is to say that I exerted fairly little judgement. Ultimately, I just wanted a sample that skewed heavily towards the most popular feeds but which would be somewhat depleted of "chat shows and celebrity stuff", as I called them.
Using Apple's charts of top podcasts as a starting point, I had claude fetch and parse feeds and their descriptions, and then dispatch subagents to do some ad-hoc classification to the effect of, essentially, "substantive content" vs "fluff". I had a much more detailed prompt than that, of course, but I'm not really counting on accuracy/adherence here.
Essentially, I know from just a cursory glance that this ad-hoc classification without human feedback has made misclassifications compared to what I would have done manually, but I'm also pretty confident that the net effect is that my sample of feeds is closer to what I had wanted than if I had done no filtering at all.
If I did want to look into trends in advertising, I would have to alter my methodology. Ads are injected dynamically at the time of download, not always present when the episode is published. So, if you wanted to watch advertising change over time, you'd want to be thinking about the time the ad was served rather than the time the podcast was published.
I'm using HTTP "If-Modified-Since". Empirically, it looks like ~50% of feeds support this. This may seem like a small thing, but consider fetching a podcast feed on a daily basis that only updates once per week -- 85% of all downloads can be replaced with
HTTP 304 Not Modifiedresponses! If you wanted to synchronize feeds hourly, then only 1 out of every 168 fetches would download anything.This might surprise you if you have been paying attention to how highly commoditized LLM inference is these days. It's true that, for LLM operations, I cannot typically beat the prices of major providers (especially on my last-gen hardware which offers less FLOPs/Watt efficiency). However, transcription is a different story. My impression is that STT API providers are aiming more at low-latency to support customers trying to run realtime voice interfaces, and maybe they aren't focusing as much on batch workloads. Whatever the reason, the upshot is that it pays to be close to the hardware here, and it's more than enough to offset the engineering time.
Interestingly, that's not uniformly true. If a person is sufficiently famous and is often written about, they may actually have a large enough foothold in semantic space that references to them are effectively disambiguated.
The same is true of other proper nouns. For example, Nvidia, currently the largest company in the world, can be referenced by name. Essentially, the embedding model "knows what Nvidia is", to anthropomorphize. Keep working your way down a list of companies sorted by market capitalization however, and before long it will likely be impossible to query by name.